
It’s occurred to me that I haven’t updated this thing in almost a year, and a lot has happened in that time. My last post left us on the North Dakota prairie during the peak of the spring wildflower bloom. Since then, I picked up the kids, camped with geocaching friends in Medicine Rocks State […]

The Prairie in Bloom
With the school year over and nice weather upon us, I’ve had some free time to get out and explore the landscape beyond Williston. I’ve been out on the prairie twice to discover the array of early wildflowers in the grasslands. This is the time of year when I feel like I could actually enjoy […]

A Spiritual Moment
My trip to the Redwoods had a profound effect on me. I can’t really explain what it was or why. I’ve been to many amazing and beautiful places never come back as humbled and rejuvenated as I had on this last trip. But everything about it just put me at ease and at awe. It […]

What’s your travel style?
When I think about the way I travel and the way others travel, there are two extremes at the ends of a spectrum: on one side, we fit in everything we can see during our limited time at a destination; on the other side, we stick to a small area and get to know it […]

What have I been up to?
It has been quite some time since I last made a post here, so I’d say I’m a bit overdue for an update. For the past two and a half years, I have been living in northwestern North Dakota. Saying this is an adjustment is an understatement. North Dakota is considerably flatter than any place […]

Fourth of July
For many years, I have spent my Fourth of July basking in the part of America that I enjoy the most: its wild and natural beauty. It started in 2011 when I explored the Hobo Cedar Grove for the first time. Then again in 2013 when I hiked Grandmother Mountain. In 2015, I spent the […]
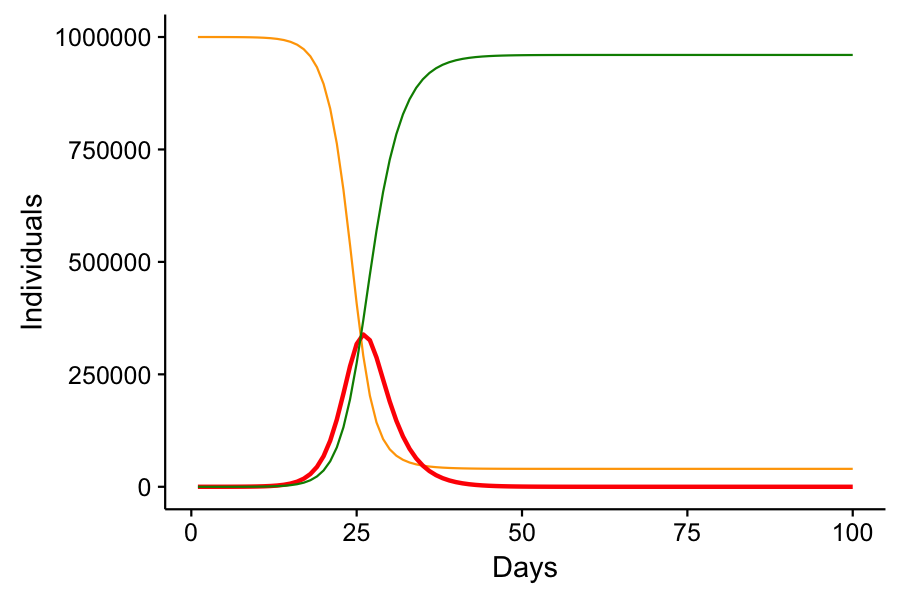
Why you’re working from home, Part 2: A Shiny Model
Immediately after I published my last post, I wasn’t content with the manner in which I conveyed the SIR model. Simply posting graphs from scenarios that I ran isn’t exciting. It’s passive, and it doesn’t actively demonstrate for the reader how social distancing does work to reduce infection rates. I wanted something interactive. Something that […]

Why you’re working from home: An introduction to epidemiological modeling
The COVID-19 virus is sweeping the world causing an equally contagious pandemic of fear and confusion. Depending on where you live, you may be ordered to stay home, going out only when necessary, or there may be no restrictions on your life, leaving it up to you to decide how to go about your day […]
Sand Mountain Trail
I don’t get out hiking or geocaching often these days. With geocaching, it makes sense. I’ve found nearly all of the geocaches in a close distance to home and town, forcing me to travel farther distances just to make a find. But when it comes to hiking, I have less of an excuse. I don’t […]

Geocaching
In case you weren’t aware, Geocaching is one of my hobbies turned obsession that fills my life with joy. Geocaching is a game in which people hide containers and post the coordinates on the web for others to enter into a GPS and go out and find. The game began in May of 2000. On […]

Adventures in Sourdough
When life prevents you from going out and adventuring, you make your own adventures at home. My latest adventure is making sourdough. Now, I could go out and obtain or buy a starter from a local bakery, but what’s the fun of that? It’s so easy to start my own from scratch, and now I […]

An update for 2018
It’s occurred to me that I haven’t been good at writing posts recently. My last update was from May, and that was subsequently my last big hiking trip. Since then, I have been incredibly busy, and that means I haven’t had as much time for fun. I did get out a few times this summer […]